Robust artificial intelligence tools to predict future cancer
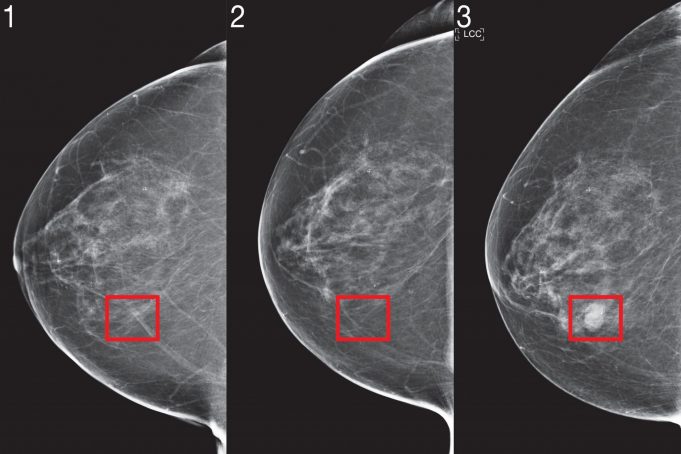
Researchers created a risk-assessment algorithm that shows consistent performance across datasets from US, Europe, and Asia.
To catch cancer earlier, we need to predict who is going to get it in the future. The complex nature of forecasting risk has been bolstered by artificial intelligence (AI) tools, but the adoption of AI in medicine has been limited by poor performance on new patient populations and neglect to racial minorities.
Two years ago, a team of scientists from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and Jameel Clinic demonstrated a deep learning system to predict cancer risk using just a patient’s mammogram. The model showed significant promise and even improved inclusivity: It was equally accurate for both white and Black women, which is especially important given that Black women are 43 percent more likely to die from breast cancer.
But to integrate image-based risk models into clinical care and make them widely available, the researchers say the models needed both algorithmic improvements and large-scale validation across several hospitals to prove their robustness.
To that end, they tailored their new “Mirai” algorithm to capture the unique requirements of risk modeling. Mirai jointly models a patient’s risk across multiple future time points, and can optionally benefit from clinical risk factors such as age or family history, if they are available. The algorithm is also designed to produce predictions that are consistent across minor variances in clinical environments, like the choice of mammography machine.
The team trained Mirai on the same dataset of over 200,000 exams from Massachusetts General Hospital (MGH) from their prior work, and validated it on test sets from MGH, the Karolinska Institute in Sweden, and Chang Gung Memorial Hospital in Taiwan. Mirai is now installed at MGH, and the team’s collaborators are actively working on integrating the model into care.
Mirai was significantly more accurate than prior methods in predicting cancer risk and identifying high-risk groups across all three datasets. When comparing high-risk cohorts on the MGH test set, the team found that their model identified nearly two times more future cancer diagnoses compared the current clinical standard, the Tyrer-Cuzick model. Mirai was similarly accurate across patients of different races, age groups, and breast density categories in the MGH test set, and across different cancer subtypes in the Karolinska test set.
“Improved breast cancer risk models enable targeted screening strategies that achieve earlier detection, and less screening harm than existing guidelines,” says Adam Yala, CSAIL PhD student and lead author on a paper about Mirai that was published this week in Science Translational Medicine. “Our goal is to make these advances part of the standard of care. We are partnering with clinicians from Novant Health in North Carolina, Emory in Georgia, Maccabi in Israel, TecSalud in Mexico, Apollo in India, and Barretos in Brazil to further validate the model on diverse populations and study how to best clinically implement it.”
How it works
Despite the wide adoption of breast cancer screening, the researchers say the practice is riddled with controversy: More-aggressive screening strategies aim to maximize the benefits of early detection, whereas less-frequent screenings aim to reduce false positives, anxiety, and costs for those who will never even develop breast cancer.
Current clinical guidelines use risk models to determine which patients should be recommended for supplemental imaging and MRI. Some guidelines use risk models with just age to determine if, and how often, a woman should get screened; others combine multiple factors related to age, hormones, genetics, and breast density to determine further testing. Despite decades of effort, the accuracy of risk models used in clinical practice remains modest.
Recently, deep learning mammography-based risk models have shown promising performance. To bring this technology to the clinic, the team identified three innovations they believe are critical for risk modeling: jointly modeling time, the optional use of non-image risk factors, and methods to ensure consistent performance across clinical settings.
1. Time
Inherent to risk modeling is learning from patients with different amounts of follow-up, and assessing risk at different time points: this can determine how often they get screened, whether they should have supplemental imaging, or even consider preventive treatments.
Although it’s possible to train separate models to assess risk for each time point, this approach can result in risk assessments that don’t make sense — like predicting that a patient has a higher risk of developing cancer within two years than they do within five years. To address this, the team designed their model to predict risk at all time points simultaneously, by using a tool called an “additive-hazard layer.”
The additive-hazard layer works as follows: Their network predicts a patient’s risk at a time point, such as five years, as an extension of their risk at the previous time point, such as four years. In doing so, their model can learn from data with variable amounts of follow-up, and then produce self-consistent risk assessments.
2. Non-image risk factors
While this method primarily focuses on mammograms, the team wanted to also use non-image risk factors such as age and hormonal factors if they were available — but not require them at the time of the test. One approach would be to add these factors as an input to the model with the image, but this design would prevent the majority of hospitals (such as Karolinska and CGMH), which don’t have this infrastructure, from using the model.
For Mirai to benefit from risk factors without requiring them, the network predicts that information at training time, and if it’s not there, it can use its own predictive version. Mammograms are rich sources of health information, and so many traditional risk factors such as age and menopausal status can be easily predicted from their imaging. As a result of this design, the same model could be used by any clinic globally, and if they have that additional information, they can use it.
3. Consistent performance across clinical environments
To incorporate deep-learning risk models into clinical guidelines, the models must perform consistently across diverse clinical environments, and its predictions cannot be affected by minor variations like which machine the mammogram was taken on. Even across a single hospital, the scientists found that standard training did not produce consistent predictions before and after a change in mammography machines, as the algorithm could learn to rely on different cues specific to the environment. To de-bias the model, the team used an adversarial scheme where the model specifically learns mammogram representations that are invariant to the source clinical environment, to produce consistent predictions.
To further test these updates across diverse clinical settings, the scientists evaluated Mirai on new test sets from Karolinska in Sweden and Chang Gung Memorial Hospital in Taiwan, and found it obtained consistent performance. The team also analyzed the model’s performance across races, ages, and breast density categories in the MGH test set, and across cancer subtypes on the Karolinska dataset, and found it performed similarly across all subgroups.
“African-American women continue to present with breast cancer at younger ages, and often at later stages,” says Salewai Oseni, a breast surgeon at Massachusetts General Hospital who was not involved with the work. “This, coupled with the higher instance of triple-negative breast cancer in this group, has resulted in increased breast cancer mortality. This study demonstrates the development of a risk model whose prediction has notable accuracy across race. The opportunity for its use clinically is high.”
Here’s how Mirai works:
- The mammogram image is put through something called an “image encoder.”
- Each image representation, as well as which view it came from, is aggregated with other images from other views to obtain a representation of the entire mammogram.
- With the mammogram, a patient’s traditional risk factors are predicted using a Tyrer-Cuzick model (age, weight, hormonal factors). If unavailable, predicted values are used.
- With this information, the additive-hazard layer predicts a patient’s risk for each year over the next five years.
Improving Mirai
Although the current model doesn’t look at any of the patient’s previous imaging results, changes in imaging over time contain a wealth of information. In the future the team aims to create methods that can effectively utilize a patient’s full imaging history.
In a similar fashion, the team notes that the model could be further improved by utilizing “tomosynthesis,” an X-ray technique for screening asymptomatic cancer patients. Beyond improving accuracy, additional research is required to determine how to adapt image-based risk models to different mammography devices with limited data.
“We know MRI can catch cancers earlier than mammography, and that earlier detection improves patient outcomes,” says Yala. “But for patients at low risk of cancer, the risk of false-positives can outweigh the benefits. With improved risk models, we can design more nuanced risk-screening guidelines that offer more sensitive screening, like MRI, to patients who will develop cancer, to get better outcomes while reducing unnecessary screening and over-treatment for the rest.”
“We’re both excited and humbled to ask the question if this AI system will work for African-American populations,” says Judy Gichoya, MD, MS and assistant professor of interventional radiology and informatics at Emory University, who was not involved with the work. “We’re extensively studying this question, and how to detect failure.”
Yala wrote the paper on Mirai alongside MIT research specialist Peter G. Mikhael, radiologist Fredrik Strand of Karolinska University Hospital, Gigin Lin of Chang Gung Memorial Hospital, Associate Professor Kevin Smith of KTH Royal Institute of Technology, Professor Yung-Liang Wan of Chang Gung University, Leslie Lamb of MGH, Kevin Hughes of MGH, senior author and Harvard Medical School Professor Constance Lehman of MGH, and senior author and MIT Professor Regina Barzilay.
The work was supported by grants from Susan G Komen, Breast Cancer Research Foundation, Quanta Computing, and the MIT Jameel Clinic. It was also supported by Chang Gung Medical Foundation Grant, and by Stockholm Läns Landsting HMT Grant.
Related Stories


